


Optimització de la predicció de CTR mitjançant l’enginyeria de funcions basada en clúster
Amb més de 500.000 recomanacions per segon, Taboola és la plataforma de publicitat nativa líder del món. Quan es tracta de recomanar contingut, triar les funcions adequades pot tenir un gran impacte. Taboola treballa amb molts editors, per exemple, notícies, compres, llocs web d’esports, etc. La característica més bàsica per representar un editor podria ser el seu identificador. L’ús de funcions bàsiques com l’identificador de l’editor no ens diu gaire sobre quines són les preferències de l’usuari. A més, l’escàs d’una característica com l’identificador de l’editor requereix moltes dades per aconseguir bons resultats. Finalment, les funcions basades en identificadors són propenses als fenòmens d’arrencada en fred, en què els editors recentment afegits no apareixen al conjunt de dades i encara no coneixen el model i, el que és més important, encara no tenen prou trànsit per al model. per extreure altres característiques significatives..
Un millor enfocament és utilitzar característiques que caracteritzen els editors pels seus articles (és a dir, notícies) i els usuaris que els visiten. Ajudar el model a entendre millor l’editor i seleccionar un contingut més personalitzat de manera eficaç, i millorar la implicació i la satisfacció dels usuaris, alhora que millorem el rendiment i la generalització dels nostres models.
En aquest bloc descriuré el procés d’anàlisi de dades per a l’extracció de funcions significatives relacionades amb l’editor per a una millor predicció del CTR.
Estar còmode amb les teves dades
Aquest viatge comença amb un conjunt de dades principal que conté informació sobre els articles recomanats per Taboola amb informació sobre l’usuari i l’editor, durant la primera setmana del 2024.
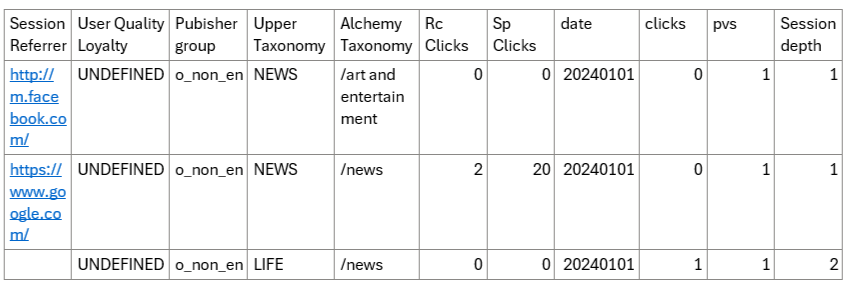
Taula 1: exemple del nostre conjunt de dades principal del primer dia de 2024.
El conjunt de dades actual conté informació com ara:
- Ubicació: el nom de la secció on apareixia l’element recomanat dins de la pàgina.
- Referent de sessió: el domini del lloc web que ha remès l’usuari a l’editor en la sessió actual.
- Clics orgànics: quantitat de clics orgànics històrics dels usuaris (és a dir, clics en articles).
- Clics patrocinats: quantitat de clics patrocinats històrics dels usuaris (és a dir, clics als anuncis).
- Pvs: quantitat de pàgines vistes de l’identificador d’element actual.
- Profunditat de sessió: nombre de pàgines per les quals va passar l’usuari fins que va arribar a la visualització de la pàgina actual.
- Clics: 0/1 per al clic de l’usuari/sense clic a l’element.
- Font/Target Upper/Alchemy Taxonomie – La categoria a la qual pertany l’article (és a dir, Esports). Source és l’article actual, Target és l’article recomanat per taboola.
A més, vaig utilitzar un altre conjunt de dades complementari per a “publisher_common_features”. Aquest conjunt de dades proporciona informació sobre les cinc principals ubicacions geològiques d’usuari habituals de cada editor, com ara el país, la ciutat, la regió i el codi DMA (per als editors dels EUA), i les cinc categories/taxonomies més habituals que llegeixen els usuaris d’aquest editor (és a dir, esports, entreteniment, etc.).
Taula 2: Exemple del nostre conjunt de dades complementàries.
Mostra d’aperitius del buffet de dades
En primer lloc, vaig filtrar el conjunt de dades principal per retenir només mostres d’usuaris que van aparèixer en més d’un dia de la setmana i que tenien valors de clics rc/sp. A més d’això, només vaig provar 250.000 mostres de cada dia de la setmana.
Un cop tinguem un marc de dades preparat, podem començar a gestionar els valors que falten i eliminar els valors atípics.
Préstec de dades del pati dels veïns
[missing values snippet]
Com podeu veure al fragment anterior, hi ha alguns valors que falten a les columnes País i Regió, i un nombre important de valors que falten a la columna Referent de sessió, els gestionarem de manera diferent.
Per al País i la Regió, que són totes dues característiques d’usuari, podem inferir alguns dels valors trobant l’ID d’usuari en una altra mostra del conjunt de dades i establint el País i la Regió d’aquesta mostra als valors que falten. Després d’aplicar aquesta tècnica, teníem un nombre molt reduït de valors que falten, de manera que podíem deixar caure aquestes mostres.
Amb la funció de referència de sessió, el cas és diferent. El valor que falta en aquesta columna assenyala que no hi ha informació sobre la derivació d’aquesta sessió, i simplement podem establir el valor d’aquestes mostres a “ALTRE”.
Adéu cua llarga!
Quan es treballa amb un conjunt de dades que es recull en funció de les sessions d’usuari en línia, és important eliminar els valors atípics, ja que aquests valors són majoritàriament robots sense intenció de fer clic al contingut suggerit.
| Clics patrocinats | Clics orgànics | |
| Abans de l’eliminació | 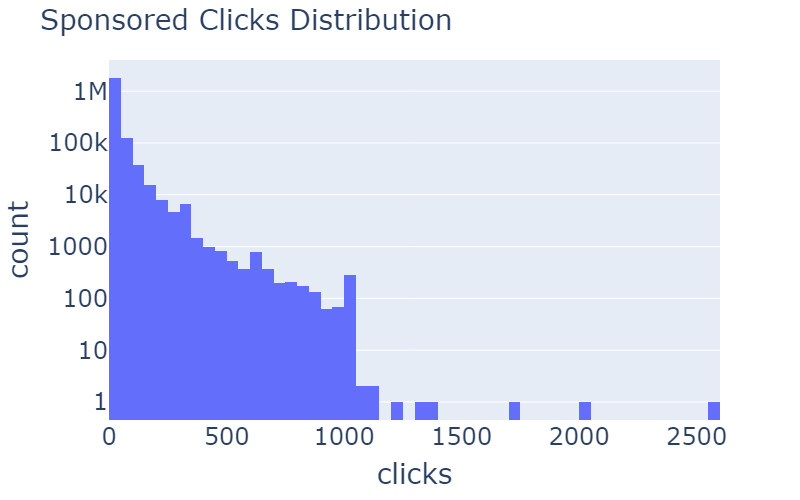 |
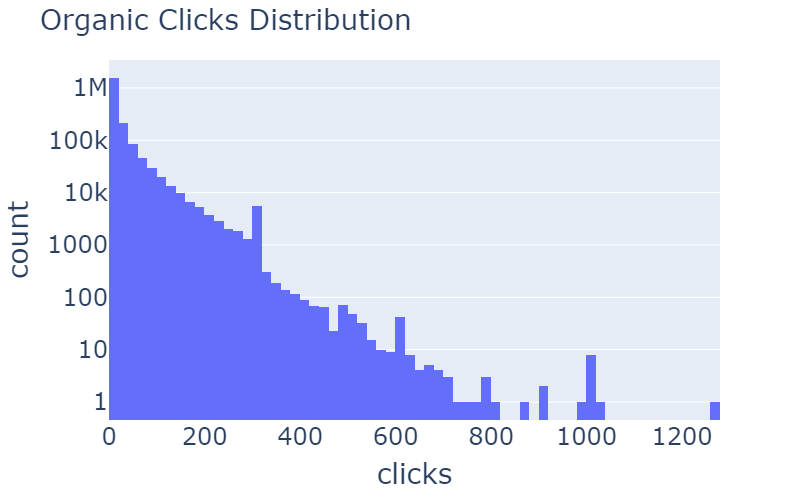 |
| Després de l’eliminació | 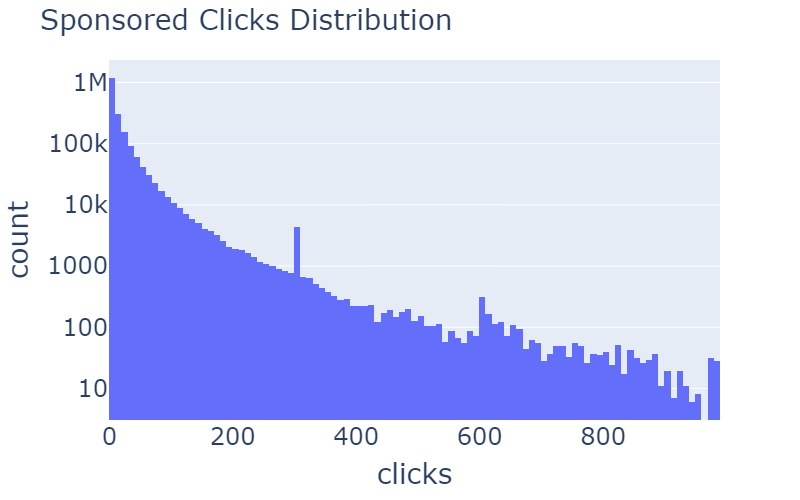 |
Taula 3: Distribució de rcClicks i spClicks abans i després de l’eliminació dels valors atípics.
A la taula 3, podeu veure exemples d’eliminació d’anomalies. A la distribució de rcClicks i spClicks hi ha cues llargues que es poden eliminar. Mitjançant l’ús d’una puntuació z de més de 20, hem obtingut aquesta agradable i gradual corba distribuïda log-normal.
Desenterrant joies amagades a la mina de dades
Com s’ha esmentat abans, volem extreure algunes característiques significatives que descriuen els nostres editors.
Comencem analitzant quines propietats d’una recomanació d’elements poden influir en el comportament de l’usuari (és a dir, els clics).
Una hipòtesi era que algun impacte pot provenir de les característiques següents:
- is_weekend*: Funció binària per a sessions de cap de setmana.
- upper_taxonomy_match*: 0/1 per a la coincidència entre la taxonomia superior d’origen i de destinació**.
- alchemy_taxonomy_match*: 0/1 per a la coincidència entre la taxonomia d’alquímia d’origen i de destinació.
- in_market: es calcula com a 0/1 per a una coincidència entre la ubicació de l’usuari, com ara: país, regió, ciutat i codi DMA
- is_sp_lover/is_rc_lover: si l’usuari tenia més d’un 40% de rcClicks i spClicks era considerat com a amants de sp/rc (és a dir, un clicker patrocinat o orgànic).
- is_sp/rc_lovers_publisher: 1 per a editors amb més del 50% dels usuaris amants de sp/rc, 0 en cas contrari.
- is_TAXONOMY_publisher: per a cada TAXONOMIA (és a dir, categoria d’article) hem afegit una característica binària si la TAXONOMIA és una de les 5 taxonomies superiors més comunes de la pàgina font.
- common_target_taxonomy: si el trànsit explicat pels usuaris per a aquesta taxonomia (és a dir, esports) d’aquest editor era superior al 70%, l’editor es considerava aquest editor de “taxonomia”. en cas contrari- “Cap”.
*Per al nostre propòsit, aquestes funcions s’utilitzaran com a funcions de calibratge/contextual
**La taxonomia és una manera de classificar els elements en grups amb característiques comunes. En el nostre cas, seran els temes principals de l’article/editor (per exemple, notícies, esports, etc…). La taxonomia superior fa referència a categories d’alt nivell, i l’alquímia es refereix a categories més detallades i específiques.
Com els editors van trobar les seves ànimes bessones
Per tal d’obtenir una mica de coneixement sobre el significat que tenen les nostres característiques, primer utilitzarem visualitzacions de les nostres dades per veure quines característiques mostren separació a les dades dels editors.
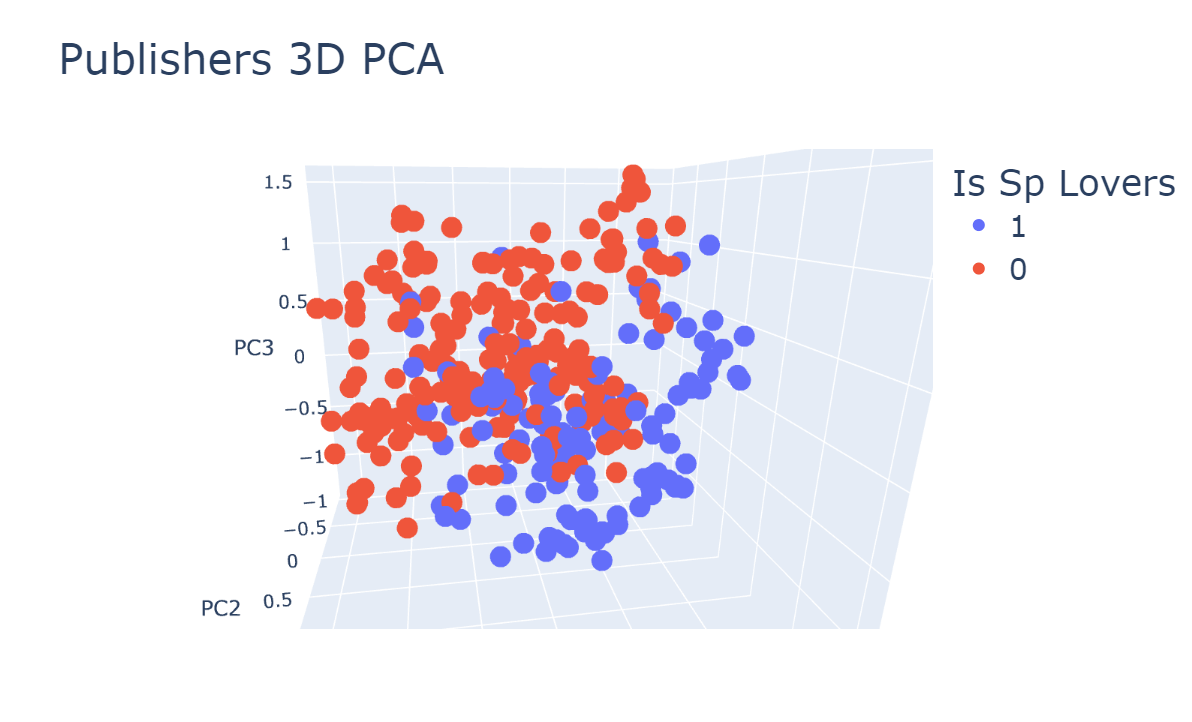
Després de realitzar una codificació única per a les característiques categòriques i escalar les característiques numèriques amb l’escalador Min-Max, vam utilitzar PCA 2D i 3D per visualitzar la distribució dels editors.
 |
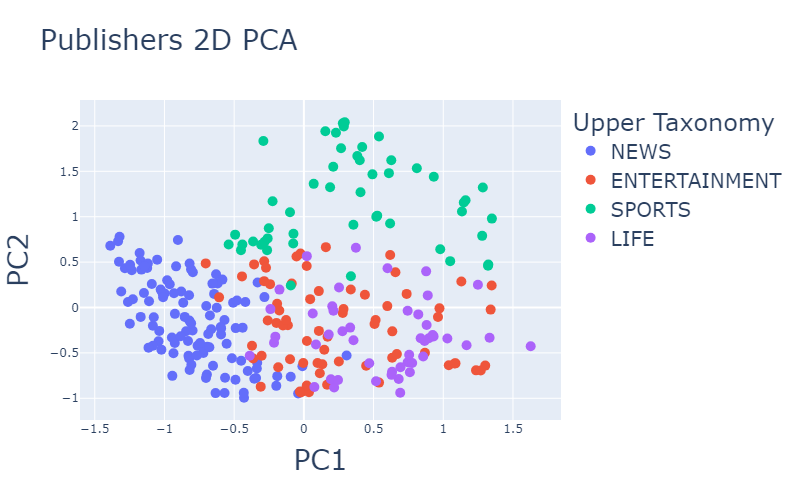 |
| Figura 1: Distribució de la representació dels editors en 2 i 3 dimensions mitjançant PCA. | |
Aquí ja podem veure alguna separació d’acord amb la taxonomia de l’editor i
si es tracta d’una editorial d’amants patrocinada.
Atès que les característiques dels editors existents no defineixen necessàriament quins editors són semblants en el context de la predicció del CTR, vaig decidir provar de representar els editors mitjançant mètodes diferents que s’ajustin millor al nostre objectiu.
Compartint usuaris com encaixades de mans secretes
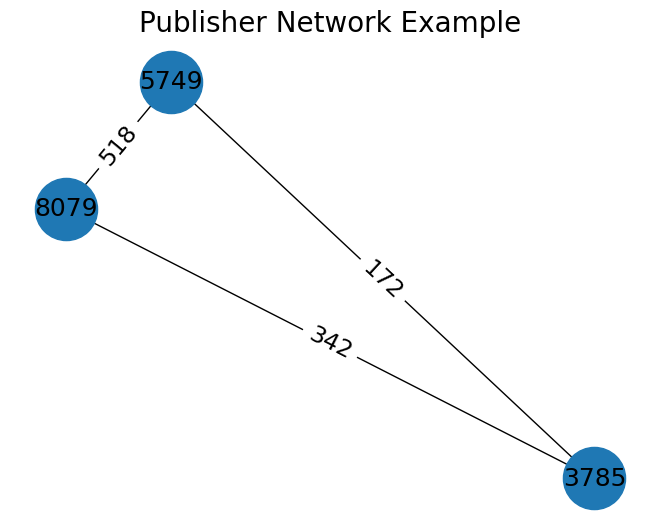
Com a part dels nostres esforços per dividir els nostres editors de manera eficaç, vam decidir representar les nostres dades com un gràfic de xarxa. En aquest gràfic, els nodes representen els editors i les vores ponderades entre dos nodes representen el nombre d’usuaris compartits entre els dos editors respectius (vegeu l’exemple a la figura 2).
Mitjançant aquest enfocament, pretenem trobar patrons i coneixements sobre per què determinats editors s’agrupen a la xarxa.
[shared users graph building snippet]
Hi ha algunes tècniques molt bones per obtenir una partició de nodes en una xarxa. Hem utilitzat el mètode Lovaina per a la detecció de comunitats.
Per evitar nodes aïllats o desconnectats i garantir una estructura de xarxa cohesionada, vam eliminar els editors amb poca connectivitat a la resta de la xarxa.
Després d’analitzar la partició, va resultar que la característica que va definir aquesta agrupació és el llenguatge de l’editor, que és una característica existent al nostre conjunt de dades.
 |
 |
| Figura 2: Exemple de la xarxa d’editors amb tres editorials, amb un nombre d’usuaris de 8079, 5749, 3785. i un nombre d’usuaris compartits de 518, 342, 172. | Figura 3: Un dibuix de la xarxa d’editorials, amb colors per als diferents grups de la partició |
Apuntar a la tasca corresponent – Predicció CTR
Vaig utilitzar un dels models de predicció de ctr coneguts, DeepFM (Guo, H., Tang, R., et al., 2017) del paquet DeepCTR. Aquest model utilitza màquines de factorització, així com xarxes neuronals profundes per predir el clic o el no clic d’elements en funció de característiques escasses i denses.
Durant aquest procés, cada valor de característica categòrica s’assigna a un espai d’inserció de mida predefinida.
Després d’entrenar el model amb les nostres dades, vaig extreure les incrustacions dels nostres articles i vaig examinar la seva agrupació mitjançant t-SNE.
Amb aquesta representació espacial incrustada dels nostres editors, esperava que les noves funcions de l’editor:
- Agrupeu els elements d’una manera diferent.
- Millora la predicció de CTR.
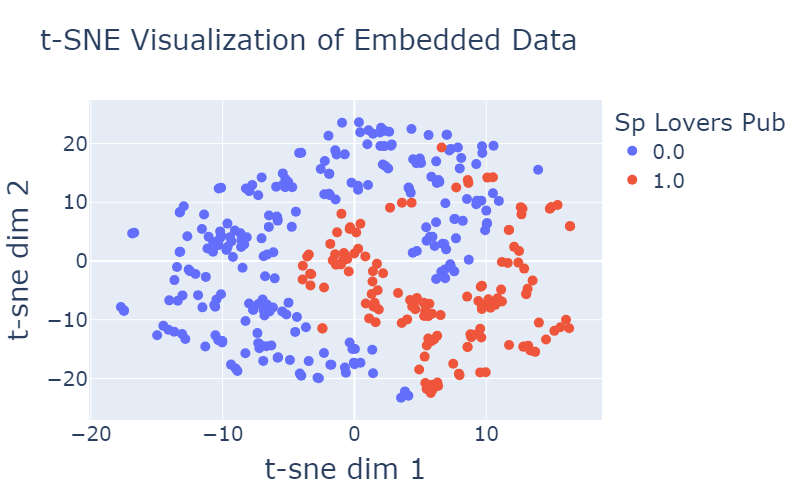
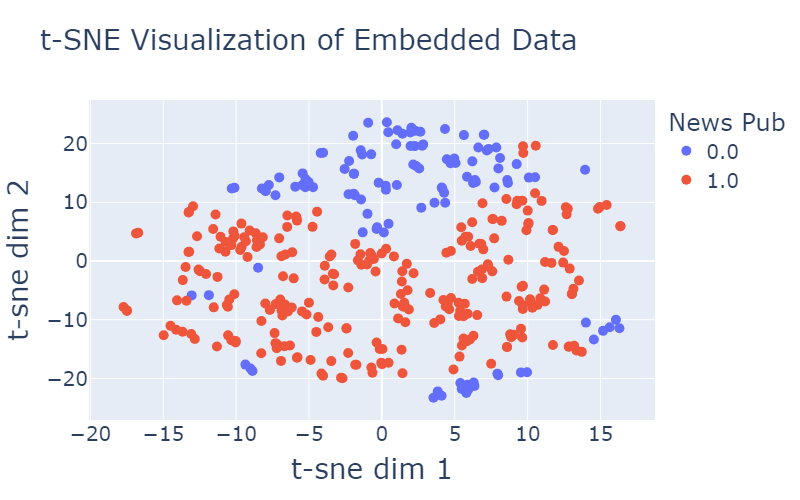
Aquí teniu un exemple de com es distribueixen els editors a l’espai d’inserció recentment format:
 |
 |
 |
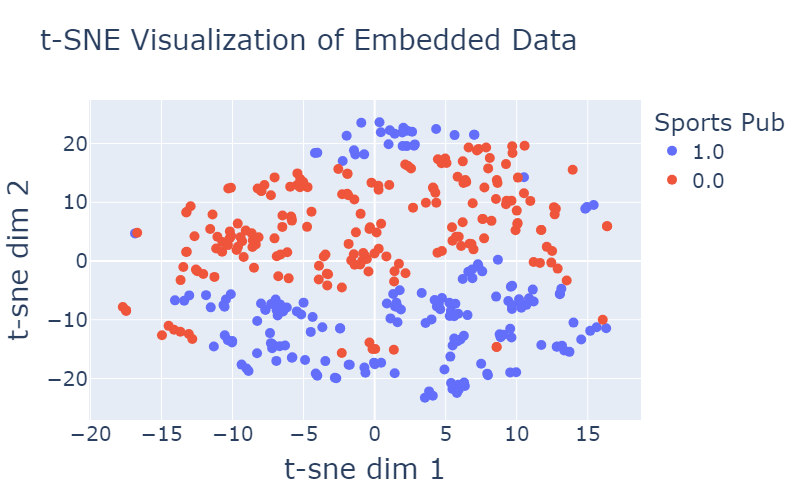 |
| Figura 4: Il·lustració de la distribució de les editorials a l’espai d’inserció. Cada punt representa un editor, amb la seva posició determinada per t-SNE. La trama està codificada per colors per ressaltar diferents característiques dels editors, com ara taxonomia com notícies o esports i si una gran part dels seus usuaris són clicadors de contingut patrocinats. | |
Com es demostra a la visualització proporcionada a la figura 4, observem una clara separació entre els punts de dades, que indica l’efectivitat de les característiques significatives incorporades a la nostra representació. Aquesta separació és un testimoni de la importància de les característiques que hem inclòs, que capturen aspectes essencials de les dades i contribueixen a la seva agrupació diferent.
El Moment de la Veritat
Per validar la meva hipòtesi, he realitzat una anàlisi comparativa entre els resultats del model original, entrenat amb el conjunt de dades original, i els d’un model modificat entrenat exclusivament en dades associades a un clúster específic. Per garantir l’equitat, tots els models van ser entrenats i provats en un nombre igual de mostres.
| Model Original | Model dedicat | Ascensor | ||
| Notícies Editores | AUC ↑ | 0,6589 | 0,6829 | 3,6% ↑ |
| Pèrdua de registre ↓ | 0,294 | 0,2709 | 7,8% ↓ | |
| Editors esportius | AUC ↑ | 0,6456 | 0,691 | 7% ↑ |
| Pèrdua de registre ↓ | 0,2821 | 0,2736 | 3% ↓ | |
| Editors d’entreteniment | AUC ↑ | 0,6405 | 0,6846 | 6,8% ↑ |
| Pèrdua de registre ↓ | 0,295 | 0,2911 | 1,3% ↓ | |
| Editors d’amants patrocinats | AUC ↑ | 0,6215 | 0,6816 | 9,6% ↑ |
| Pèrdua de registre ↓ | 0,3129 | 0,2714 | 13,2% ↓ | |
Taula 4: Comparació entre diferents models que es van formar en clústers específics d’editorials.
Com esperàvem, els models que es van entrenar i provar només amb mostres d’un clúster ben definit, van tenir un rendiment significativament millor que el que es va entrenar amb les dades no agrupades.
Separació amb estil
Un suggeriment vàlid que es pot derivar dels resultats de la taula 4 és separar el conjunt de dades de formació en grups dedicats d’editors per categoria comuna. Això pot beneficiar el model i, finalment, donarà lloc a recomanacions més adaptades.
“Embolicant-ho: la part on diem “adéu” i “gràcies per totes les dades!””
En el meu viatge per millorar les recomanacions de contingut, vaig inspeccionar un enfocament de clúster basat en dades, per tal de trobar funcions d’editor significatives a la xarxa de Taboola. Vaig analitzar les interaccions dels usuaris, les ubicacions i els tipus de contingut per trobar pistes subtils que poguessin augmentar les recomanacions i mantenir la implicació dels nostres usuaris. Hem descobert patrons interessants entre les editorials. Això obre possibilitats interessants per generar recomanacions més personalitzades.
Amb aquesta finalitat, hem obtingut una millora real en el rendiment dels nostres models, amb millores notables observades en mètriques clau com l’AUC i la pèrdua de registre. Aquests resultats positius validen l’eficàcia del nostre enfocament i reforcen la nostra confiança en el potencial de la agrupació basada en dades per millorar les recomanacions de contingut.
Agraïments
Aquesta publicació del blog va ser creada per Ofri Tirosh i dirigida pels mentors de Taboola Gali Katz i Dorian Yitzhach com a part del Programa de pràctiques de Starship juntament amb el Departament d’Enginyeria de Sistemes d’Informació i Programari de la Universitat Ben-Gurion.
Referències
Guo, H., Tang, R., Ye, Y., Li, Z. i He, X. (2017). DeepFM: una xarxa neuronal basada en màquines de factorització per a la predicció de CTR. arXiv preimpressió arXiv:1703.04247.
Related Post